
 William Hersh, MD, Professor and Chair, OHSU
William Hersh, MD, Professor and Chair, OHSU
Blog: Informatics Professor
Twitter: @williamhersh
When I teach about the features of search engines like PubMed, I often quip that if you use the limit function to narrow your search to randomized controlled trials (RCTs), which are the best evidence for medical and health interventions, and you still have many retrievals, there is probably some enterprising researcher who has done a systematic review on the topic. Some actually worry that we have too many systematic reviews these days, not always of the greatest quality.(1) But such reviews, especially when done well, can not only be important catalogs of research on a given topic but also provide an overview of the breadth and quality of studies done.
Sure enough, we have started to see systematic reviews on artificial intelligence (AI) and machine learning (ML) applications. A new systematic review covers all of the RCTs of interventions of AI applications.(2) I hope the authors will keep the review up to date, as one limitation of systematic reviews published in journals is that they become out of date quickly, especially in rapidly moving areas such as AI.
As we know from evidence-based medicine (EBM), the best evidence for the efficacy of interventions (treatment or prevention) comes from RCTs. Ideally, these trials are well-conducted, generalizable, and well-reported. EBM defines four categories of questions that clinicians ask: intervention, diagnosis, harm, and prognosis. As such, there are other clinical questions that can be answered about AI beyond those about interventions. For example, can AI methods improve the ability to diagnose disease? Can AI identify harms from environment, medical care, etc.? And finally, can AI inform the prognosis of health and disease? Ultimately, however, AI interventions must be demonstrated experimentally to benefit patients, clinicians, and populations. There are of course some instances when RCTs are infeasible so observational studies may be justified.
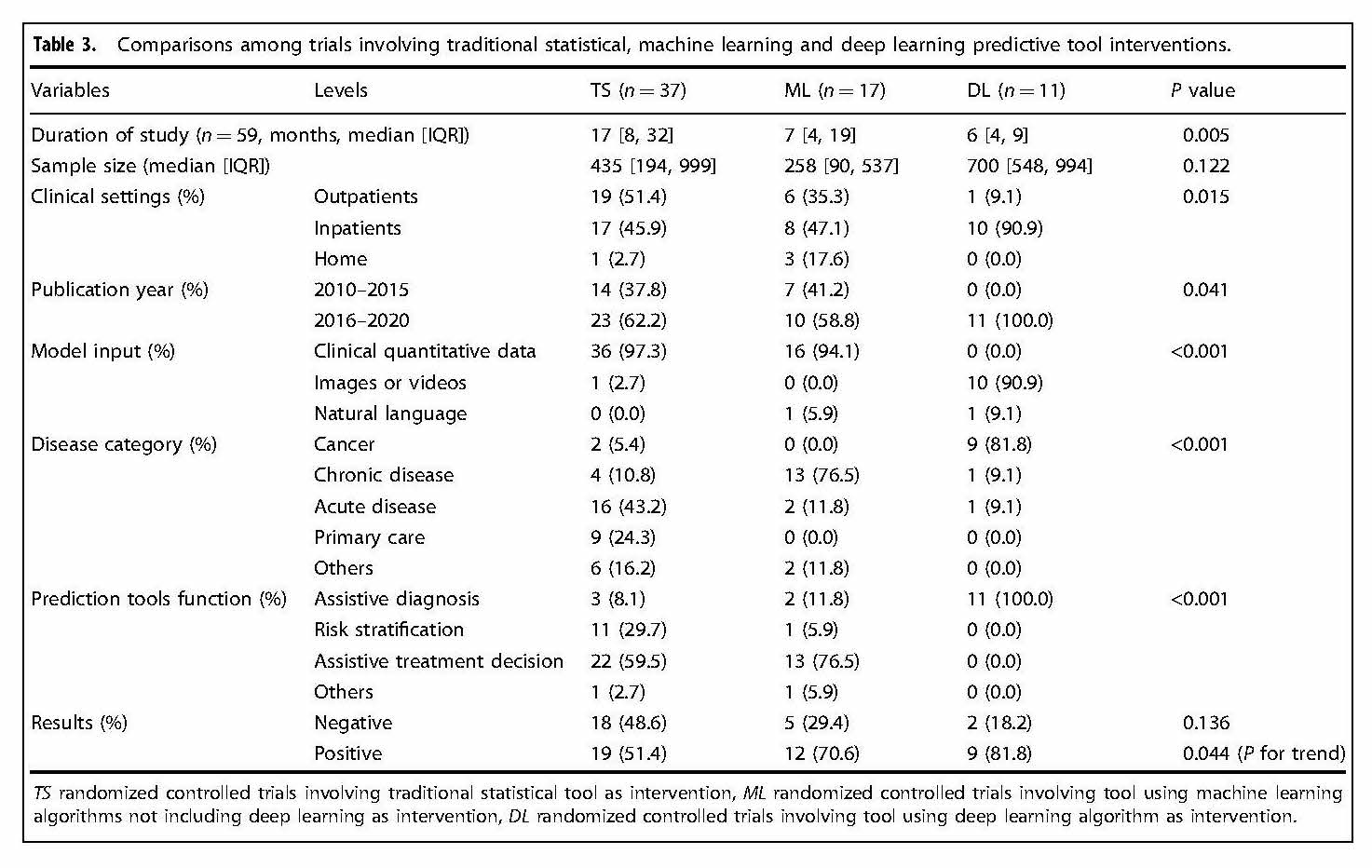
In this context, we can review a recently published systematic review of interventions using AI clinical prediction tools of Zhou et al.(2) This systematic review categorized AI methods into three groups: traditional statistical (TS), mostly regression; machine learning (ML), all ML but deep learning; and deep learning (DL), i.e., applications using multi-layered “deep” neural networks. TL and MS tools were found to be used for three functions: assistive treatment decisions, assistive diagnosis, and risk stratification, whereas DL tools were only assessed for assistive diagnosis.
Typical as happens in most systematic reviews, the authors found over 26,000 papers published and retrieved by their broad MEDLINE search, but of those, there were only 65 RCTs identified. Once identified, the 65 trials were reviewed for a number of characteristics. One important characteristic was whether or not studies demonstrated a benefit for AI, i.e., had a positive result. Of course, counting numbers of positive vs. negative results is not necessarily an indicator of the value or generalizability of a particular method of AI or any other clinical intervention for that matter. Nonetheless, the authors did find that 61.5% of the RCTs had positive results and 38.5% negative results.
As AI can be used for many conditions and functions in medicine, it is important to get a sense of what was studied and what tools were used. The authors found use for AI in a variety of disease categories: acute disease (29%), non-cancer chronic disease (28%), cancer (17%), primary care (14%), and other conditions (12%). Of the predictive tool function used, use was most often for assistive treatment decisions (54%), followed by assistive diagnosis (25%) and risk stratification (19%). There were the most studies used for TS (57%), followed by ML (26%) and DL (17%). These differences may reflect the more recent development and use of ML and especially DL. The rates of positive studies for the tool types were highest for DL (82%), followed by ML (71%) and TS (51%), although it should be noted that the rate of positive results was also inversely related to the number of trials for each tool type.
A table in the paper shows that there were differences by tool categories. TS tools were mostly likely to be used with clinical quantitative data (97%), applied in acute disease (43%) and primary care (24%), and used for assistive treatment decisions (60%) followed by risk stratification (30%). ML tools were also most likely to be used by clinical quantitative data (94%), applied in chronic disease (77%), and used for assistive treatment decisions (77%). DL tools were most likely to be used with imaging data (91%), applied in cancer (91%), and used exclusively for assistive diagnosis (100%). In particular, the DL studies almost exclusively evaluated assistance of gastrointestinal endoscopy, with all nine such RCTs showing positive results and the two trials of other applications and diseases having negative results. Also of note, only two of the 65 RCTs made use of natural language data for input, one ML and one DL.
Systematic reviews typically appraise included studies for risk of bias, or in other words, the quality of their methods to produce an unbiased result. This provides confidence that the research methods were robust and well-reported so readers can have confidence that the results obtain are true. Unfortunately, there were a number of concerns that led to 48 (74%) of the trials being classified as having high or indeterminate risk of bias. This was due to a number of factors:
- One-third of the trials carried out no sample size estimation to determine what would be the number of subjects needed to achieve a statistically significant benefit
- Three-fourths of the trials were open-label, so had no masking of the AI system from its users
- Three-fourths did not reference the CONSORT statement, a 37-item checklist widely used for reporting the details of RCTs and recently extended for AI trials
- Three-fifths did not apply an intent-to-treat analysis, which evaluates subjects in the study groups into which they were originally assigned
- Three-fourths did not provide reference to a study protocol for the trial
The rate of outcomes of studies for low risk of bias trials was somewhat comparable to the overall rates, with positive outcomes in 63% of TS, 25% of ML, and 80% of DL trials.
What can be concluded from this systematic review? We certainly know from the vast amount of other literature that a large number of predictive models have been built using AI techniques and shown to function well for a wide variety of clinical conditions and situations. We probably cannot do an RCT of every last application of AI. But at this point in time, the number and variety of RCTs assessing benefit for interventions of AI is modest and uneven. While a number of positive results have been demonstrated, the studies published have not been dispersed across all of the possible clinical applications of AI, and three-fourths of the reports of the trials show indeterminate or high risk of bias. DL methods in particular must be assessed in the myriad of areas in which data sets have been developed and models trained.
There are some problems with the systematic review itself that mar the complete understanding of the work. Table 2 of DL interventions has data missing in its leftmost column that connects the data in the column to its original reference. This table also does not include a recent paper by Yao et al.,(3) which was likely published after the review was completed. It is also difficult to use the data in Supplementary Table 4 of ML interventions, which is provided in a PDF file that is difficult to read or browse. In addition, while the paper references a high-profile study by Wijnberge et al.,(4) it is not listed in ML table. This study may well be classified as TS, but this demonstrates another limitation of the systematic review, which is that there is no data or table that details TS interventions. The authors were kind enough to provide Excel files of the DL and ML tables, but they really should be part of the online materials for the systematic review. I do hope they or someone will keep the review up to date.
As it stands, this systematic review does give us a big-picture view of the clinical use and benefit for AI at this point in time, which is modest, disproportionate, and based on studies using suboptimal methods. We can conclude for now that AI predictive tools show great promise in improving clinical decisions for diagnosis, treatment, and risk stratification but comprehensive evidence for the benefit is lacking.
This systematic review also highlights a point I have written about in this blog before, which is that AI interventions need translation from basic science to clinical value. In particular, we need clinically-driven applications of AI that are assessed in robust clinical trials. There of course must also be attention to patient safety and to clinician workflow. In general, we need robust AI and RCT methods that are replicable and generalizable, and of course we must conduct implementation and trials from a health equity standpoint.
For cited references in this article, see original source. Dr. Hersh is a frequent contributing expert to HealthIT Answers.