
 By Adam Culbertson
By Adam Culbertson
Twitter: @HHSIDEALab
The promise of electronic health records (EHR) is that they will improve quality and lower cost. The basis of this claim is in part due to a presumption of EHR interoperability. Patient matching has been identified as a critical barrier to interoperability. Patient matching, also called entity resolution or record linkage, refers to the act of accurately linking individuals to their health data located in various disparate electronic health databases.
Patient matching is more like a verb than a noun, as matching is more of an activity than a specific technology. At the most basic level, patient matching is asking this one question hundreds of times over and over: “Do these two health records refer to the same patient?” My work as a Healthcare Information Management Systems Society (HIMSS) Innovator-in-Residence focuses on understanding and innovating around this question and the patient matching process. Check out my project page for a broader introduction to patient matching and my work.
Though patient matching can be described in simple terms, the consequences of getting it wrong can be catastrophic. A recent article noted several cases of patient matching gone awry. The consequences can range from humorous in the most benign cases to extreme cases leading to fatal medical errors. The financial cost due to the inability to match records can be as high as $1 million dollars for organization with multiple hospitals.
The solution to patient matching isn’t singular as there are many aspects to consider. Patient matching is the downstream process of many variables including the capture, structure, transport and ultimately the merging of patient data into a larger body of data. Another way to think of this process is like a stream that flows down river. Matching a patient to their medical records is the downstream action of a complex set of upstream events. Each of the subsequent events affects the ability to link a patient to their health records downstream.
The use of standards, such as an emerging technology known as HL7 Fast Healthcare Interoperability Resources® (FHIR) pronounced “Fire,” can play a role. Before you can match the data, you have the upstream process of capture, structure, transport that data. FHIR is a means to both structure and transport of the data that can help to achieve interoperability.
FHIR’s Promise to Structure and Transport Data
The first component is the structure of the data. The FHIR draft standard (or any standard for that matter) specifies how certain data elements should be structured and formatted.
One of the first steps that must be undertaken before any data can be linked is the data must be pre-processed for data quality errors and formatted to a common structure for an apples-apples comparison. For example, humans intuitively know that the phone listed as 202.1234 and 202-1234 is likely the same thing. However, computers are not as good at such tasks. Matching algorithms commonly use data elements such as First Name, Last Name, Phone, and Date of Birth to determine whether a pair of records represent the same patient. First name and last name are typically more straightforward. But take the example of DOB which can be represented in different formats like MM/DD/YYYY or DD/MM/YYYY. As an example, FHIR can simplify the data clean-up and pre-processing by pre-specifying the format the data should be in. These examples help explain how FHIR can help with the matching process.
A simple problem such as formatting different dates becomes a complex issue as the number of systems to be integrated increases and each of these can have different date formats. FHIR specifies how the data should be structured, or how the information must be constrained. These common formats can be used between computer systems to ensure consistency of the data so that when you compare individual attributes you are comparing apples-to-apples and that difference between attributes are due to differences in values and not format. Choosing a specific format can become complicated but in general, you can’t compare two elements for the purpose of matching if they are not in the same format.
The next area that FHIR can help with is the transport of the data. FHIR is built on the HTTP protocol and uses a RESTFUL Design approach.
The HTTP protocol is the same protocol that is used to power the world wide web . The simplest way to think of this is a client-server relationship. The client asks the server a question and the server responds with a standardized message. In the figure below, the individual (client) asks a question to the server that gives a standard response back to that question. For example, in a clinical context you ask a question, “Do you have patient John Doe?” [in your electronic medical record]. The system responds with a message “Yes, I have John Doe.” You could then ask “Do you have John Doe’s blood glucose results?” That is a simple way one could think of the client server relationship.
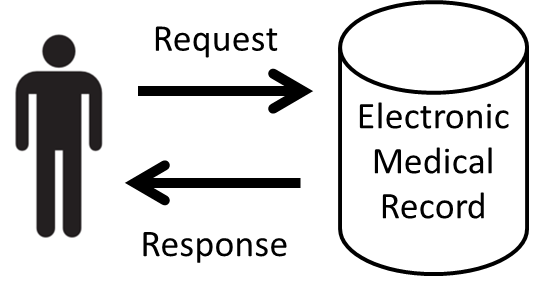 FHIR is built from a RESTFUL design approach, which is basically a certain style a software architecture uses to design a software system. The RESTFUL design architecture is the general principle that is used to design many of the applications on the web, such as Facebook and Twitter. RESTFUL design uses several methods to access data such as GET, PUT, DELETE. Take GET, for example. GET is a command that can be used to go to a database resources, which could be a EHR database. Data is stored on these resources in the form of XML and JSON, which are open data standards. FHIR has some early promise to solve the problems of structure and transport of the data. This is advantageous as many web developers have an understanding of this development approach as opposed to an older version of an HL7 standard.
FHIR is built from a RESTFUL design approach, which is basically a certain style a software architecture uses to design a software system. The RESTFUL design architecture is the general principle that is used to design many of the applications on the web, such as Facebook and Twitter. RESTFUL design uses several methods to access data such as GET, PUT, DELETE. Take GET, for example. GET is a command that can be used to go to a database resources, which could be a EHR database. Data is stored on these resources in the form of XML and JSON, which are open data standards. FHIR has some early promise to solve the problems of structure and transport of the data. This is advantageous as many web developers have an understanding of this development approach as opposed to an older version of an HL7 standard.
Although FHIR is not the only solution to the challenge of the structure and transport of data, it makes use of the many open and freely available web standards that are available today. Since FHIR leverages existing standards, which are open source, this makes it an ideal platform for developing prototype solutions. Lastly, it is important to design applications for the future. FHIR is easy to use and implement, making it a great mechanism to develop prototype solutions to the challenge of patient matching. The goal of interoperability is the seamless, simple, and secure transfer of patient data through the health care system.
Building a Matching System into the FHIR Framework
While FHIR can help with the structure and transport of the data, it doesn’t offer a complex matching solution. To reach the goal of interoperability you need structure, transport of the data, but also the ability to merge or match the data. Once you have the data that has been cleaned and formatted, you need a matching system to handle data this, which is a computationally complex process. This is where FHIR and the data matching process come together. In order to do complex matching, you need to integrate a complex matching algorithm into this existing framework that FHIR is developed around.
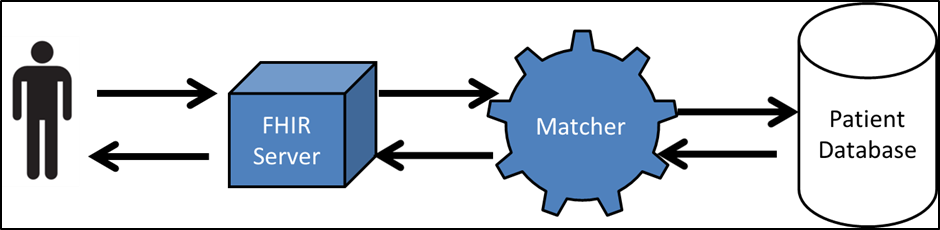 Depending on the use case, the type of matching algorithm you implement could be vastly different. This is analogous to selecting a car. A car that is good for driving in the desert is very different than a car that you would take to the race track. The way someone would train for a marathon is very different than the way someone would train as a sprinter.
Depending on the use case, the type of matching algorithm you implement could be vastly different. This is analogous to selecting a car. A car that is good for driving in the desert is very different than a car that you would take to the race track. The way someone would train for a marathon is very different than the way someone would train as a sprinter.
One of the challenges to patient matching is getting the right matching approach designed for different types of medical databases as they all vary in data quality and types of attributes available for matching. In order to advance interoperability, a standard API for matching algorithms should be considered. This could ease the implementation of different matching algorithms to the different types of matching problems. In addition, validation of patient matching algorithms around the specific use cases could increase the level of assurance of end users. Thus the combination of a complex matching solutions integrated with the FHIR standard could be get us much closer to complete interoperability solution. This would allow providers access to the right patient’s data at the right place in a safe and secure manner. There would ultimately be a great deal of work that subsequently would need to occur to achieve this vision. In order to help work on this challenge, we have hosted a previous workshop Patient Data Matching on FHIR Testing Event at the HIMSS Innovation Center in Cleveland on August 14th.
Get Involved
The HHS IDEA Lab is hosting a two-day FHIR code-a-thon happening April 1-2, 2016 in Washington DC. At the code-a-thon, developers from Federal and State-based organizations will have the opportunity to collaborate with entrepreneurs, startups and research organizations to build cool solutions that leverage the HL7 FHIR API. To learn more and register, please visit the code-a-thon event webpage.
About HIMSS
Healthcare Information and Management Systems Society (HIMSS) is a global, cause-based, not-for-profit organization focused on better health through information technology (IT). HIMSS leads efforts to optimize health engagements and care outcomes using information technology. HIMSS produces health IT thought leadership, education, events, market research and media services around the world. Founded in 1961, HIMSS encompasses more than 61,000 individuals, of which 79% work in healthcare provider, governmental and not-for-profit organizations across the globe, plus over 640 corporations and 400 not-for-profit partner organizations, that share this cause. HIMSS, headquartered in Chicago, serves the global health IT community with additional offices in the United States, Europe, and Asia.
This article was originally published on HHS Idea Lab and is republished here with permission.